Datenbank-Familien
Relationale Datenbanken
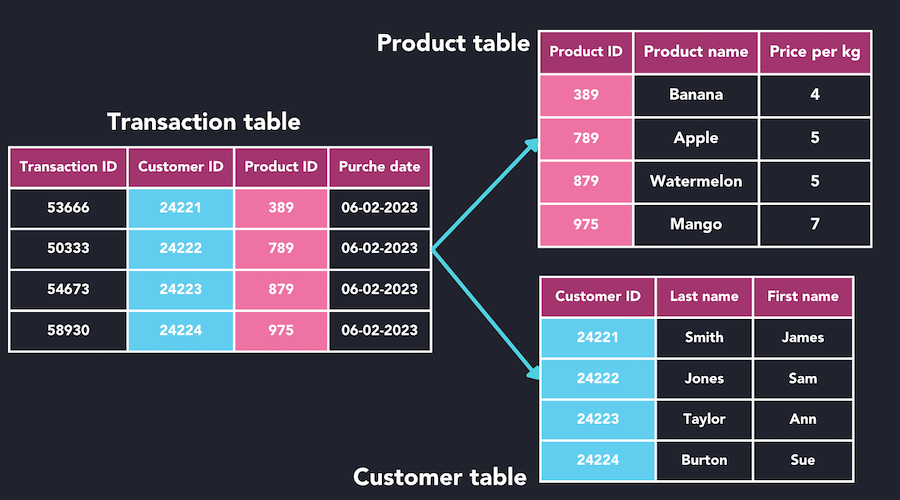
- Daten sind in zwei-dimensionalen Tabellen organisiert
- beliebige Verknüpfungen von mehreren Tabellen mit
JOINmöglich - für hohe Datenkonsistenz ausgelegt (Verfolgung des ACID-Modell)
- vertikale Skalierung / Scale up
- Kapazitätserhöhung durch Hinzufügen zusätzlicher Ressourcen zum Server
- Beispiele/Produkte
- MySQL
- MariaDB
- Postgresql
- MS SQL
- ...
Orientierung an Daten und wie sie gespeichert werden
- vorhergehende vollständige Entwicklung des Datenbankschemas
SQL
-
Structured Query Language
-
wird von relationalen Datenbanksystemen benutzt
-
standardisierte Abfragesprache mit ACID-Konformität
-
keine Partitionierung - keine Verteilung auf verschiedenen Servern
Vorteile
- sinnvoll für strukturierte Daten
- transaktionssicher dank ACID-Modell
NoSQL
Not Only SQL
-
sind horizontal skalierbar: Duplizierung/Erweiterung von Server-Kapazität
-
Schema-Freiheit: man ist nicht an ein Schema wie in relationen Datenbanksystemen gebunden
-
anderes Konsistenzmodell als ACID-Modell: BASE-Modell
-
nicht relational und somit keine beliebigen JOINs
Orientierung an Verwendung der Daten
Vorteile
- Schema-loser Entwurf ergibt hohe Flexibilität
- sinnvoll für unstrukturierte Daten
- hohe Verfügbarkeit durch horizontale Skalierung (Datenverteilung über mehrere Nodes)
- einfache Replikation/Partitionierung
Nachteile
- eingeschränkte Abfragemöglichkeiten
NoSQL-Datenbank-Typen
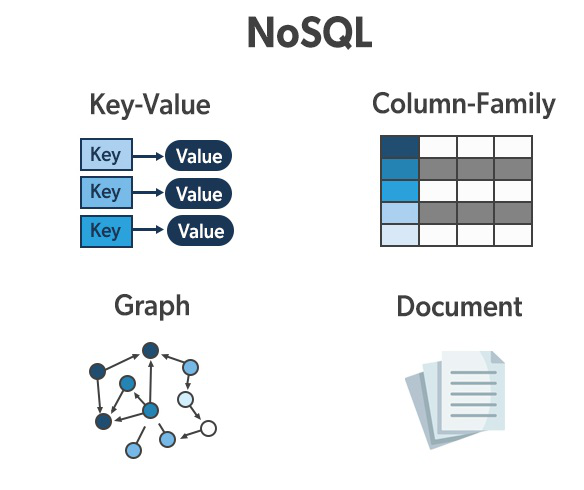
Key-Value
-
Speicherung von Daten als Schlüssel-Wert-Paare
-
am schnellsten, da sie sehr einfach sind
-
Beispiele/Produkte
- Redis
- Amazon DynamoDB
-
Anwendungen
- Caching (Session-Daten, API-Responses)
- Echtzeit-Analysen und Leaderboards
- Konfigurations- und Sitzungsverwaltung
- IoT-Datenverarbeitung mit schnellen Lese- und Schreibzugriffen
Document
-
speichern Dokumente als JSON-Daten
-
Beispiele/Produkte
- MongoDB
- CouchDB
-
Anwendungen
- Content-Management-Systeme
Wide Column / Columnar
-
zweidimensionaler Schlüssel-Wert-Speicher
-
Speicherung von Daten in Spalten
-
Spalten-Format der verschiedenen Zeilen kann unterschiedlich sein
-
Beispiele/Produkte
- HBase
- Apache Cassandra
- Google's Bigtable
-
Anwendungen
- Big-Data-Analysen
- Empfehlungssysteme und personalisierte Werbung
Graph
-
für sehr verknüpfte Daten
-
bestehen aus Knoten (Nodes) und Kanten (Relationships / Edges) dazwischen
-
Nodes und Relationships können Eigenschaften in Form von Key-Value-Paaren besitzen
-
man kann gut entlang der Relationships durch Nodes navigieren
-
Beispiel/Produkt
- Neo4J
-
Anwendungen
- Soziale Netzwerke und Verbindungen zwischen Nutzern
- Empfehlungs-Engines
Sonstige
-
in-memory
- z.B. EhCache
-
Search
- z.B. Lucene, Solar
Workflow
Man sollte zuerst wissen, wie die Daten später wieder aus dem System herausgelesen werden sollen.
→ wenig Datenmodellierung nötig, fundamentale Strukturänderungen sind nachträglich auch noch möglich → dafür hat man nachher eingeschränkte Abfragemöglichkeiten
CAP-Theorem
Consistency
Partition-Tolerance