Indexing
Index
-
zusätzliche Datenstruktur
-
beschleunigt Suchvorgänge
-
Vergleich mit einem Stichwortverzeichnis in einem Buch: ohne Index müsste man alle Seiten durchsuchen, mit Index findet man relevante Stellen sofort
-
Verhinderung des vollständigen Durchsuchens einer Tabelle (Full Table Scan)
-
Indexierung verbessert die Suchgeschwindigkeit erheblich, aber beeinträchtigt Änderungsoperationen
-
Verwendung sowohl in relationalen als auch in NoSQL-Datenbanken
Vor- und Nachteile
Vorteile
- massive Beschleunigung von manchen Suchvorgängen
Nachteile
- bei Änderungen an Tabelle müssen alle Indexe aktualisiert werden
Arten von Indexen
-
B-Tree-Index:
- flexibel für viele Abfragen
- aber langsamer als Hash-Index für
=
-
Hash-Index:
- sehr schnell für exakte Schlüsselvergleiche
- aber nicht für Bereichsabfragen nutzbar
B-Tree Index
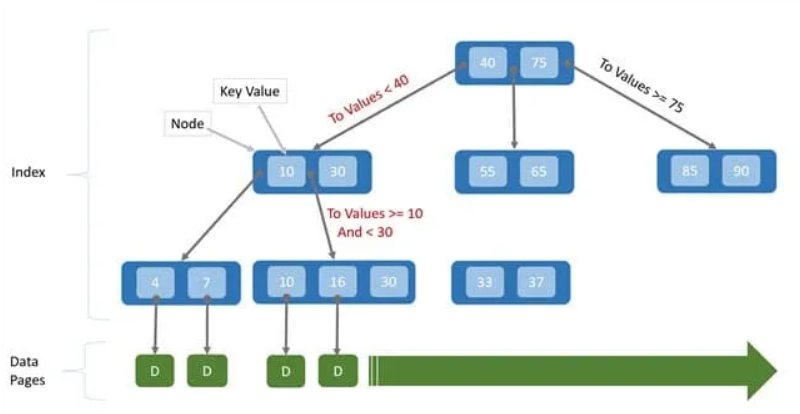
- baumartige Struktur
- ermöglicht effiziente sortierte Abfragen
- ermöglicht schnelle Suche durch logische Unterteilung der Daten
- geeignet für Abfragen mit:
=,<,<=,>,>=,BETWEEN- teilweise für
LIKE(z. B.LIKE 'Pat%'funktioniert, aberLIKE '%Pat%'nicht)
Hash-Index
- verwenden eine Hash-Funktion, um direkt die Speicheradresse eines Werts zu berechnen
Beispiel:
- Für den Namen
"Lisa"wird aus den ASCII-Werten eine Hash-Adresse berechnet (393 % 5 = 3). - Statt die ganze Tabelle zu durchsuchen, kann direkt auf den Speicherplatz zugegriffen werden.
- Falls ein anderer Name denselben Hash-Wert hat (z. B.
"Lasi"), entsteht eine Kollision, die mit einer verketteten Liste gelöst wird.
Vorteil
- extrem schnell für
=-Abfragen
Nachteil
- ungeeignet für Bereichsabfragen (
<,>,BETWEEN) - Risiko von Kollisionen
- unterschiedliche Werte können denselben Hash-Wert haben, sodass mehrere Einträge durchsucht werden müssen